好些小项目都要用到selenium,每个项目都是根据当前项目需求稍微封装下来用,后面觉得每次都根据当前需求封装一个嫌麻烦,干脆就做一个能满足大部分场景需求的,每个项目都可以直接调用,省的每个项目都要单独写一个。兼容Windows、Linux;python3.7-3.11,其他版本未测试。
由于需要大部分项目需求,把常用的操作都封装进去了,包括自定义ua、传入cookie、等待(隐式等待、显式等待)、定位元素、输入、点击等等,后面会有详细介绍。支持自动下载chromedriver驱动,不再需要手动下载解压。
部分功能演示:
自动下载chromedriver
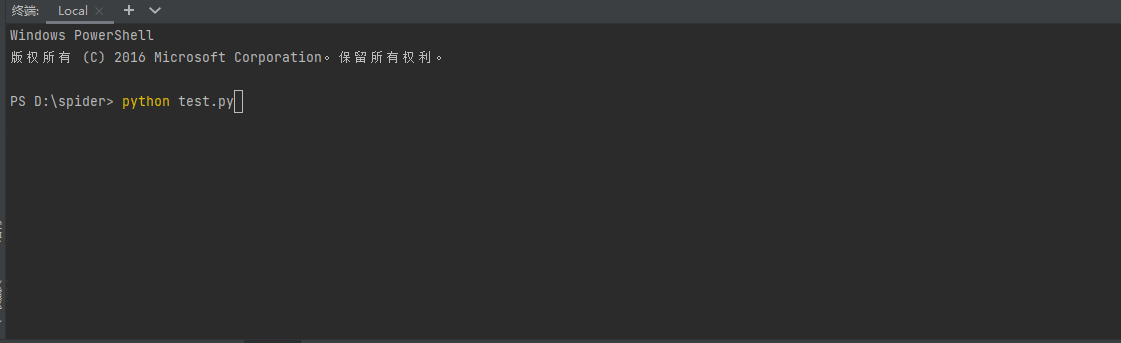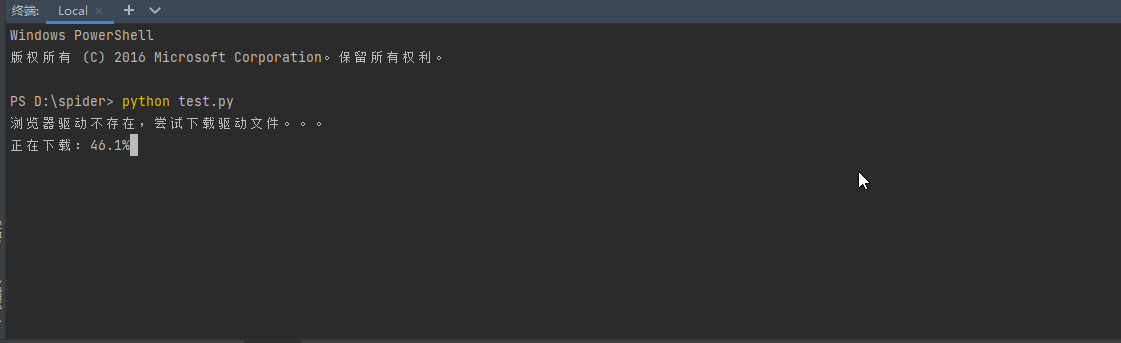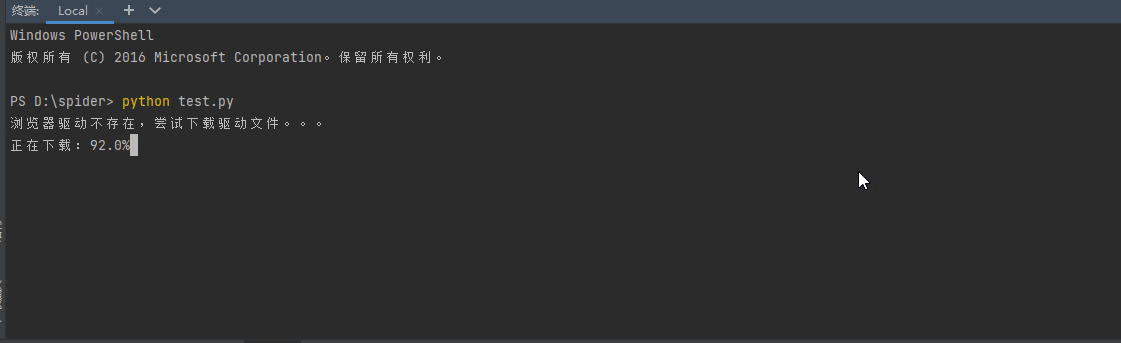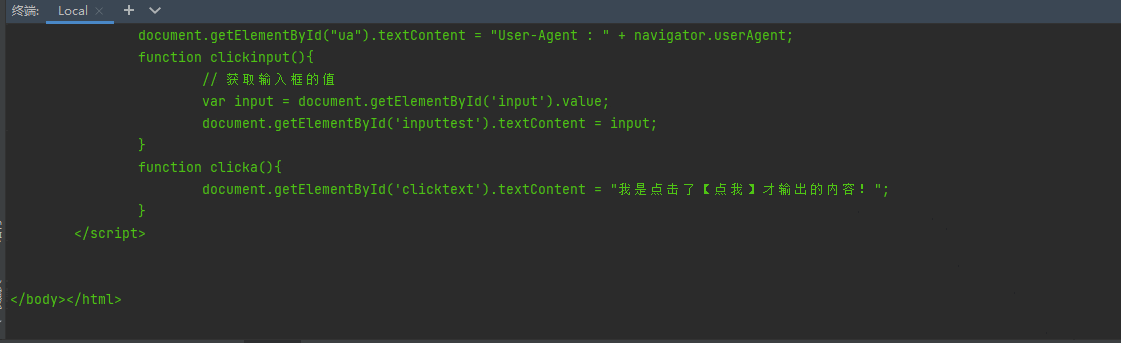
如果chromedriver版本跟chrome版本不匹配也会自动下载相对应的版本
常用操作
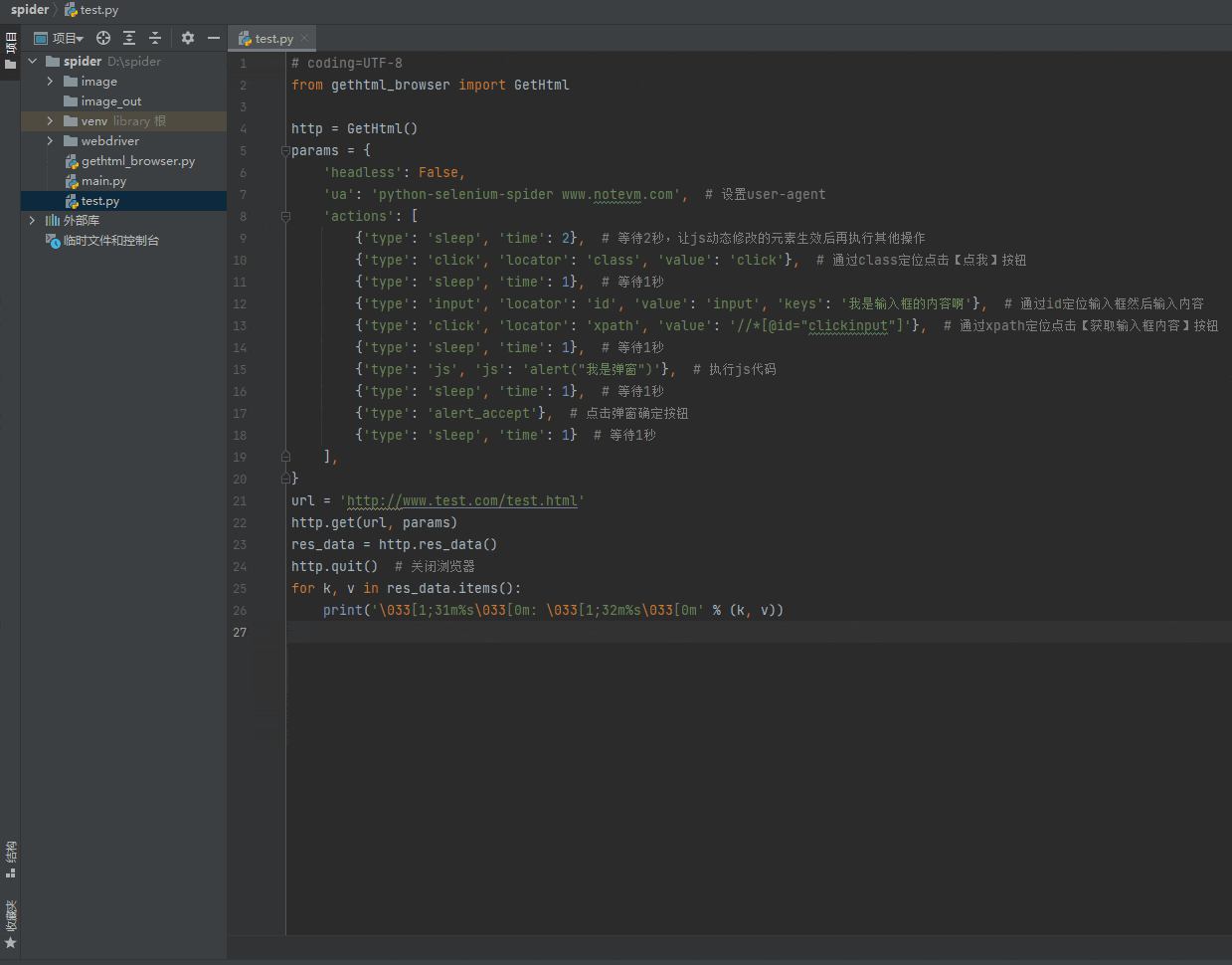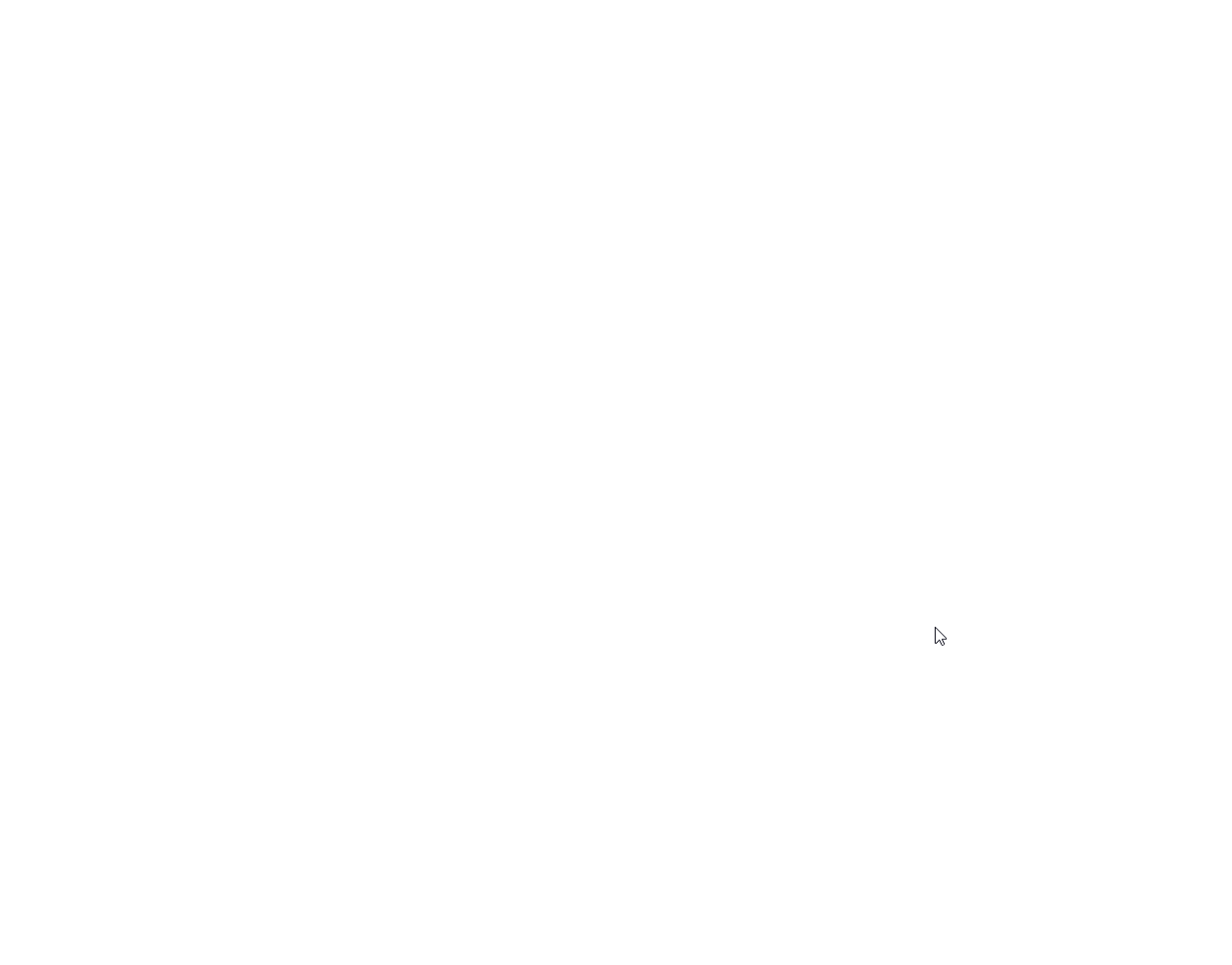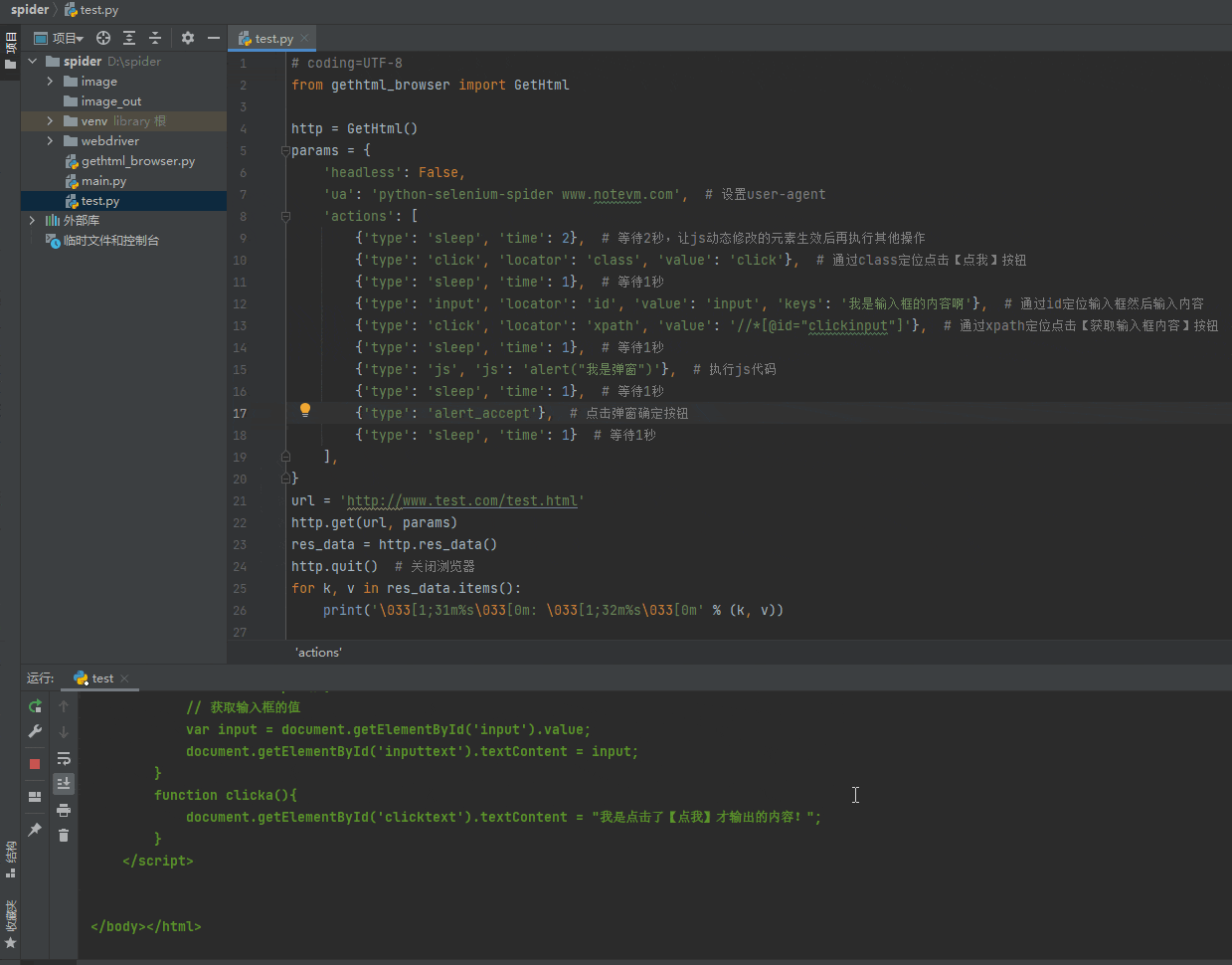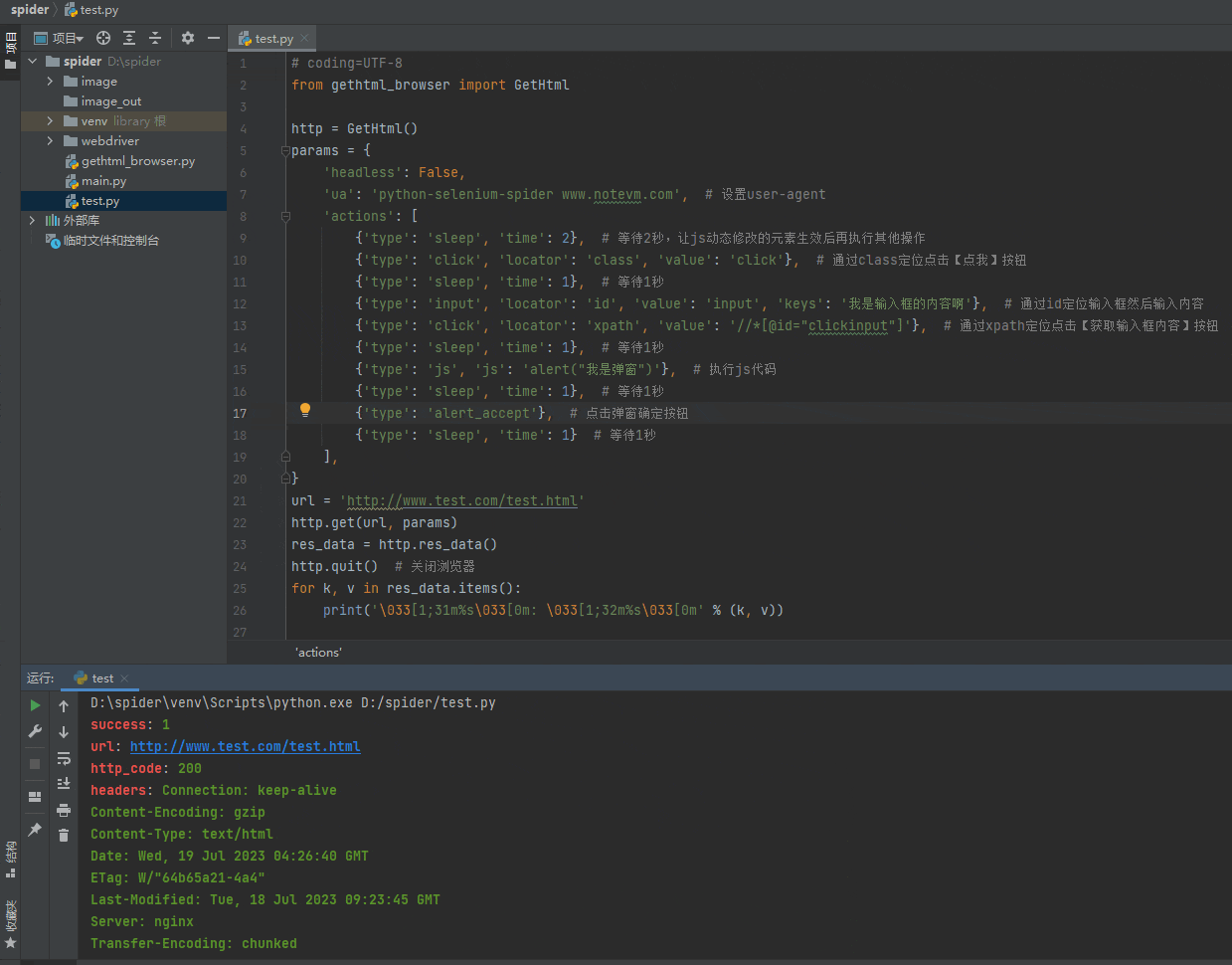
输入框也可以逐个输入

截图,截图也可以只截取某个元素

长截图

录屏图片实在是太大了,多了的话我云服务器这小水管实在是撑不住,其他的看下面的介绍吧。
请求示例:
# coding=UTF-8
from gethtml_browser import GetHtml
http = GetHtml()
actions = [
# 通过css选择器定位点击搜索图标,显示出搜索输入框
{'type': 'click', 'locator': 'css', 'value': 'body > header > div > div.collapse.navbar-collapse > div > div.navbar-search-icon.j-navbar-search > i'},
{'type': 'sleep', 'time': 1}, # 等待1秒
# 通过class定位输入框然后输入selenium,每个字符输入间隔0.05秒
{'type': 'input', 'locator': 'class', 'value': 'navbar-search-input', 'keys': 'selenium', 'input_wait': 0.05},
# 通过xpath定位点击搜索图标
{'type': 'click', 'locator': 'xpath', 'value': '/html/body/header/div/div[2]/form/div/button'}
]
params = {
'ua': 'python-selenium-spider www.notevm.com', # 设置user-agent
'incognito': True, # 使用无痕模式
'actions': actions, # 打开网页后需要执行的各种操作
}
url = 'https://www.notevm.com/'
# 返回数组,可以通过res['success']判断是否有异常,值为1的话,res包含http.res_data()的数据,如果为0会包含错误信息。
res = http.get(url, params)
"""
如果没有其他特定需求,也可以不传入params
res = http.get(url)
http.action(actions) # 打开网页后要执行的操作可以不放在params里,打开网页后通过http.action()方法执行
"""
current_url = http.url() # 获取当前页面url(如果页面有跳转就是跳转后的)
http_code, headers = http.headers() # 获取http状态码跟响应头
text = http.text() # 获取html
res_data = http.res_data() # 返回字典,包含上面所有数据
http.quit() # 关闭浏览器,一定要执行这个,不然可能会有残留的chrome进程
自动下载chromedriver说明:
默认通过淘宝的镜像地址下载,如果嫌下载速度慢,想用通过官方地址下载,可以在打开网页前设置chromedriver下载地址
http = GetHtml()
http.chromedriver_source='google'
# 然后再打开网页
http.get(url, params)params参数说明:
chrome_info(字典):
设置chrome浏览器信息,正常情况不需要传入这个参数,当某些情况程序检测不到chrome安装信息(目前我没遇到过)的时候可以手动传入chrome路径、版本号(其实chrome安装路径暂时用不到,预留功能);或者chrome大版本号刚更新,chromedriver还没更新到相应的大版本但是兼容上一个版本的时候可以手动传入上一个版本的版本号。
'chrome_info': {'path': '/opt/google/chrome/google-chrome', 'version': '114.0.5735.199'}ua(字符串):
自定义用户代理(User Agent),模拟不同浏览器或设备的访问。
'ua': 'selenium-spider www.notevm.com'cookie(字典&json):
传入cookie信息
'cookie': {'host': 'www.notevm.com', 'token': '123456'}set_cookie_type(整数):
传入cookie的方式,1或2,1无需刷新页面即可生效(但是某些网站无效),2需要刷新页面才能生效。默认为1
'set_cookie_type': 1headless(布尔值):
使用无头模式(不设置默认不使用无头模式)
'headless': Truemobile(字符串):
模拟手机访问,需要使用浏览器已有的设备信息。
'mobile': 'iPhone 12 Pro'disable_js(布尔值):
是否禁用js(不设置默认不禁用)
'disable_js': Truedisable_image(布尔值):
是否禁止加载图片(不设置默认不禁用)
'disable_image': Truedisable_gpu(布尔值):
是否禁用gpu(不设置默认不禁用)
'disable_gpu': Trueincognito(布尔值):
是否使用无痕模式(不设置默认不使用无痕模式)
'incognito': Truewindowsize(字符串):
窗口大小(不设置默认全屏,无头模式的话默认1920×1080)
'windowsize': '1366,768'proxy(字典):
该功能最后更新时间:2023-08-23
设置代理访问
默认使用http代理,如果是其他类型的(https、socks4、socks5)可以通过传入type元素指定代理类型,不传入type就是使用http代理。
使用http代理访问,有两种方式,一种是直接传入代理地址列表,一种是传入传入代理文件路径。多个代理会随机取一个来使用。
代理地址格式
需要验证:
用户名:密码@127.0.0.1:8080;空密码:用户名@127.0.0.1:8080
无需验证:
127.0.0.1:8080
在地址中指定代理类型:
如果地址中设置了代理类型的话,则使用地址中设置的类型
http://127.0.0.1:8080
https://127.0.0.1:8080
socks4://:127.0.0.1:8080
socks5://127.0.0.1:8080
传入代理列表:
'proxy': {'address': ['192.168.1.1:1111', 'user@192.168.1.1:1112', 'user:123456@192.168.1113'],'type': 'https'}传入代理文件路径:
文件里代理地址一行写一个。
'proxy': {'file': './proxy.txt', 'type': 'socks5'}action(列表):
打开网页后需要执行的各种操作,这一步可以放到params里面,也可以通过http.action(actions)来执行。
'actions': [
{'type': 'input', 'locator': 'id', 'value': 'input', 'keys': '我是输入框的内容啊'},
{'type': 'click', 'locator': 'xpath', 'value': '//*[@id="clickinput"]'},
]
# actions可以放到params里面,也可以通过http.action()方法提交
http.action(actions)
action参数说明:
元素定位支持id、class、name、tag、css选择器、xpath
参数示例:
actions = [
{'type': 'click', 'locator': 'class', 'value': 'swiper-slide-prev"'}, # 通过class定位元素并点击
{'type': 'js', 'js': 'alert("虚拟笔记-www.notevm.com")'}, # 执行js代码
{'type': 'input', 'locator': 'xpath', 'value': '//*[@id="kw"]"]', 'keys': 'notevm.com'}, # 通过xpath定位输入框然后输入内容
]sleep:
强制等待,等同于time.sleep()
[{'type': 'sleep', 'time': 10}]implicitlywait:
隐式等待
[{'type': 'implicitlywait', 'time': 10}]webdriverwait:
显式等待
[{'type': 'webdriverwait', 'locator': 'xpath', 'value': '//*[@id="kw"]', 'time': 10}]click:
点击
[{'type': 'click', 'locator': 'xpath', 'value': '//*[@id="kw"]'}]input:
输入内容
[{'type': 'input', 'locator': 'xpath', 'value': '//*[@id="kw"]', 'keys': 'notevm.com', 'input_wait': 0.1}]input_wait是逐个字符输入,类型可以是字符串、整数型、浮点型。可以固定时间,也可以输入一个时间段,'input_wait': '0.1-0.9'。
js:
执行js代码
[{'type': 'js', 'js': 'alert("我是弹窗")'}]alert_accept:
点击弹窗的确定按钮
[{'type': 'alert_accept'}]alert_dismiss:
点击弹窗取消按钮
[{'type': 'alert_dismiss'}]get:
打开链接
[{'type': 'get', 'url': 'https://www.notevm.com/'}]create_window:
创建并切换到新标签
[{'type': 'create_window'}]切换到新标签后打开指定url
[{'type': 'create_window', 'url': 'https://www.notevm.com/'}]window:
切换标签
[{'type': 'window', 'window': 'last'}]first:切换到第一个标签
last:切换到最后一个标签
index:切换到起始标签(一般情况跟first一样)
iframe:
切换到iframe
[{'type': 'iframe', 'locator': 'xpath', 'value': '//*[@id="kw"]'}]parentframe:
切换到父级frame
[{'type': 'parentframe'}]defaultcontent:
切换到默认frame
[{'type': 'defaultcontent'}]scroll:
滚动页面,可以指定滚动的距离、滚动到指定的元素还有滚动到页面底部。
1、指定滚动距离:
[{'type': 'scroll', 'scroll_type': 'coord', 'value': {'x': 0, 'y': 1000}, 'dist': 100, 'wait': 0.1}]2、滚动到指定元素:
[{'type': 'scroll', 'scroll_type': 'element', 'value': {'locator': 'xpath', 'value': '//*[@id="kw"]'}, 'dist': 100, 'wait': 0.1}]3、滚动到页面底部
[{'type': 'scroll', 'scroll_type': 'bottom', 'dist': 100, 'wait': 0.1}]dist是每次滚动的距离,默认100
wait是每滚动dist设置的距离后间隔的时间,默认0.1
截图
截取当前页面:
screenshot = http.screenshot('./screenshot.png')screenshot方法有3个参数:
save_path,element,return_base64
save_path:保存图片的路径,默认不保存。
element:截取指定元素的定位信息。
return_base64:是否返回使用base64编码的图片,默认不使用base64编码。
长截图
长截图方法fullscreenshot的参数跟screenshot方法一样。
长截图需要使用无头模式才行,不然只能截到当前页面。
screenshot = http.fullscreenshot('./screenshot.png')截取指定元素位置:
screenshot-wrap = http.fullscreenshot('./screenshot-wrap.png', element={'locator': 'xpath', 'value': '//*[@id="wrap"]/div[1]/main/section[1]'})返回base64编码过的图片:
screenshot = http.screenshot('./screenshot.png', return_base64=True)获取数据:
current_url = http.url() # 获取当前页面url(如果页面有跳转就是跳转后的)
http_code, headers = http.headers() # 获取http状态码跟响应头
text = http.text() # 获取html
res_data = http.res_data() # 返回字典,包含上面所有数据获取弹窗文本:
alert_text = http.alert_text(default='')参数default是没有弹窗的话返回的默认值,不设置默认是None。
其他说明:
现有功能不能满足的情况下,可以通过http.driver来实现。比如获取网页标题:
title = http.driver.title目前能满足我所有项目的需求,如果后续有新的需求或者有更新都会同步更新到这里来。
代码:
原创文章,作者:小哆啦,如若转载,请注明出处:https://www.notevm.com/a/7013.html
