- 2022.06.08
- 增加代理功能
- 2022.08.30
- 增加支持使用分块编码(响应头包含Transfer-Encoding: chunked)的网站
需要selenium封装的朋友可以移步到这里查看:

为了新项目学习Python,使用urllib库抓取网页内容,项目中如果每次抓取内容都用原生写的话会有一堆重复代码,就做了个简单的封装,顺便记录一下。目前能满足项目使用,如果以后有更新的话都会同步到这里。
废话不多说,直接上代码
# coding=UTF-8
import os
import random
import gzip
import zlib
import urllib.parse
import urllib.request
from urllib.error import URLError, HTTPError
class GetHtml:
def get(self, url, params={}):
if 'data' in params:
# 把字段转换为query_string格式
data = urllib.parse.urlencode(params['data'])
# 拼接url
url = urllib.parse.urljoin(url, data)
return self.__request(url, None, params)
def post(self, url, params={}):
# 编码,不设置默认utf8
charset = params.get('charset', 'utf8')
# POST数据
data = params.get('data', {})
if isinstance(data, dict):
# 把字段转换为query_string格式
data = urllib.parse.urlencode(data).encode(charset)
elif isinstance(data, str):
# 字符串转换为bytes格式
data = data.encode(charset)
return self.__request(url, data, params)
def auto(self, url, params={}):
# 自动判断get还是post
if 'data' in params:
return self.post(url, params)
else:
return self.get(url, params)
# 随机获取一个代理地址
def proxy(self, proxys):
if 'file' in proxys:
# 代理地址写在文件里
if os.path.isfile(proxys['file']):
# 文件存在
proxylist = []
f = open(proxys['file'], 'r', encoding='utf-8')
for line in f.readlines():
line = line.strip()
proxylist.append(line)
f.close()
proxyaddr = proxylist[random.randint(0, len(proxylist)-1)]
return proxyaddr
else:
exit('error: 代理文件不存在!')
else:
proxyaddrs = proxys['address']
proxyaddrs = proxyaddrs if isinstance(proxyaddrs, list) else list(proxyaddrs) # 将代理转为列表
proxyaddr = proxyaddrs[random.randint(0, len(proxyaddrs) - 1)] # 随机取一个代理地址
return proxyaddr
def __request(self, url, data, params):
# 发送请求
headers = params.get('headers', {})
# User-Agent
if 'ua' in params:
# 优先使用params里设置的ua
headers['User-Agent'] = params['ua']
elif 'User-Agent' not in headers:
# 没有设置ua,使用默认的ua
headers[
'User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
# Cookie
if 'cookie' in params:
headers['Cookie'] = params['cookie']
# 请求超时,默认10秒
timeout = params.get('timeout', 10)
# 代理
if 'proxy' in params:
proxyaddr = self.proxy(params['proxy']) # 随机获取一个代理地址
proxy_support = urllib.request.ProxyHandler({'http': proxyaddr, 'https': proxyaddr})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
req = urllib.request.Request(url=url, data=data, headers=headers)
try:
response = urllib.request.urlopen(req, timeout=timeout)
res = response.read()
if response.getheader('Transfer-Encoding') == 'chunked':
# 分块编码
encoding = response.getheader('Content-Encoding')
if encoding == 'gzip':
res = gzip.decompress(res)
elif encoding == 'deflate':
res = zlib.decompress(res)
return res.decode("utf8")
except HTTPError as e:
return 'Error : code %s' % e.code
except URLError as e:
return 'Error : Reason %s' % e.reason
except Exception as e:
return 'Error : %s' % e
调用方法
写个简单的php来测试效果
通过http://www.test.com/test.php访问
<?php
echo 'SERVER : ';
print_r($_SERVER);
echo 'POST : ';
print_r($_POST);
echo 'COOKIE : ';
print_r($_COOKIE);GET
http = GetHtml()
url = 'http://www.test.com/test.php?name=notevm'
# get的传参也可以写成字典
# data = {'name': 'notevm','user': 'admin'}
# params = {'data': data}
# html = http.get(url, params)
html = http.get(url)
print(html)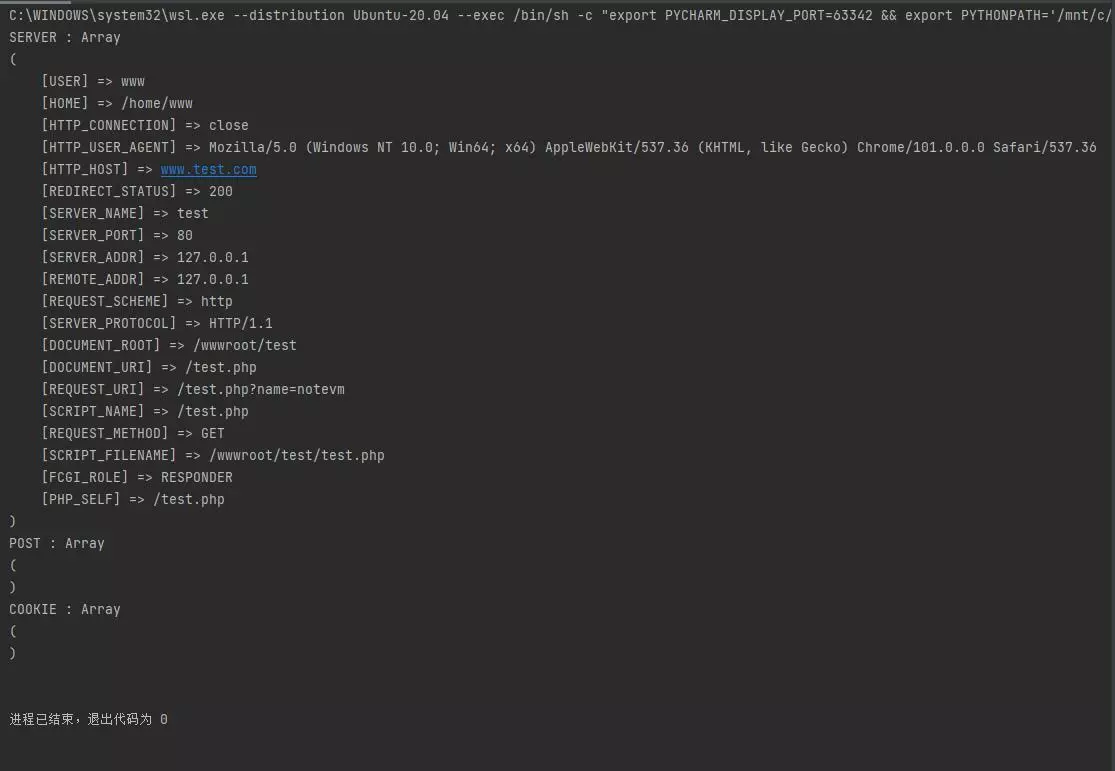
POST
http = GetHtml()
url = 'http://www.test.com/test.php'
data = {
'site': 'www.notevm.com',
'name': 'notevm',
'pass': '123456'
}
# post请求的data也可以是字符串类型
# data = "site=www.notevm.com&name=notevm&pass=123456"
params = {
'data': data
}
html = http.post(url, params)
print(html)
带User-Agent、Cookie
http = GetHtml()
url = 'http://www.test.com/test.php'
data = {
'site': 'www.notevm.com',
'name': 'notevm',
'pass': '123456'
}
params = {
'data': data,
'ua': 'python www.notevm.com',
'cookie': 'user=notevm;url=www.notevm.com'
}
html = http.get(url, params)
print(html)
自定义header信息
http = GetHtml()
url = 'http://www.test.com/test.php'
headers = {
'token': 'notevm-123456'
}
params = {
'headers': headers,
}
html = http.get(url, params)
print(html)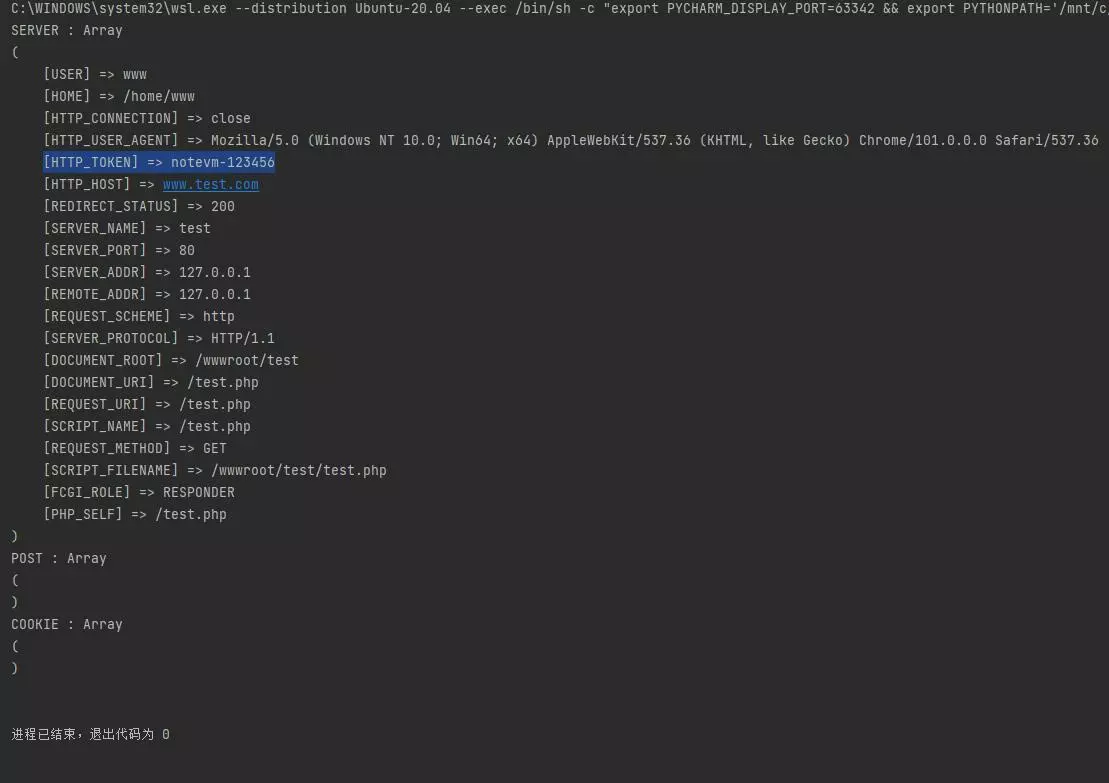
自动
http = GetHtml()
url = 'http://www.test.com/test.php?name=notevm'
# get
# get请求把参数写在url,不要在params传入data,传入data会以post的方式请求
html = http.auto(url)
print(html)
# post
data = {
'site': 'www.notevm.com'
}
params = {
'data': data
}
html = http.auto(url, params)
print(html)
更新功能示例
一次设置多个代理地址会随机取一个来使用
http = GetHtml()
url = 'http://www.test.com/test.php?name=notevm'
# 方法1:代理地址写在列表
proxy = {
'address': [
'192.168.1.1:8881',
'192.168.1.2:8882',
'192.168.1.3:8883'
]
}
# 方法2:代理地址写在txt里,一行写一个代理地址,格式:ip:port 例如:192.168.1.1:8881
proxy = {
'file': './proxy.txt'
}
params = {
'proxy': proxy
}
html = http.get(url, params)
print(html)原创文章,作者:小哆啦,如若转载,请注明出处:https://www.notevm.com/a/5693.html
